Enterprises face a host of challenges when moving agentic workflows powered by large language models (LLMs) from prototype to production at scale. While early-stage demos may showcase impressive capabilities, real-world deployment demands rigorous attention to data quality, security, compliance, and operational reliability. Generating test datasets that are tailored to specific product requirements and organizational policies is essential for systematically evaluating model performance and ensuring that LLM outputs align with business needs and regulatory standards. Robust guardrails must be put in place to proactively prevent risks such as data leakage, prompt injection, and model hallucinations, while also enforcing privacy and ethical boundaries. Ensuring compliance with industry regulations and internal governance frameworks is critical, as LLMs often process sensitive enterprise data and must operate within clearly defined access controls and audit trails.
Plurai, a member of the NVIDIA Inception program for startups, offers a platform designed to help enterprises move agentic workflows from prototype to production at scale. By automatically generating test datasets tailored to specific product specifications and policies, Plurai ensures agentic applications are rigorously stress-tested from every angle before deployment. The platform provides detailed analysis to identify failures and performance gaps, prioritize improvements, and compare outcomes across experiments, enabling teams to enhance application performance using simulated data that aligns with business needs. Combined with NVIDIA NIM, NVIDIA Nemotron reasoning models, Plurai’s platform empowers enterprises to ship agents faster while maintaining reliability and control.
Enterprises face a growing demand to validate, stress-test, and fine-tune their conversational agents at scale across use cases, platforms, and edge conditions. Plurai’s IntellAgent framework directly addresses this need by offering a powerful, automated environment to simulate diverse, real-world interactions and systematically uncover failure points before agents reach production.
IntellAgent transforms agent development into a structured, data-driven discipline. It enables teams to test agents against thousands of edge-case scenarios, measuring performance across multiple dimensions including accuracy, robustness, and conversational fluency. By leveraging synthetic and user-informed interactions, the framework delivers a rigorous assessment of agent behavior across a wide range of intents, tones, and domain complexities.
Key features include automated generation of high-impact test conversations, comprehensive analytics across conversation flows, and seamless integration with existing LLM-based agents. With IntellAgent, enterprises can proactively identify and prioritize improvements, accelerate time to production, and ensure dependable user experiences.
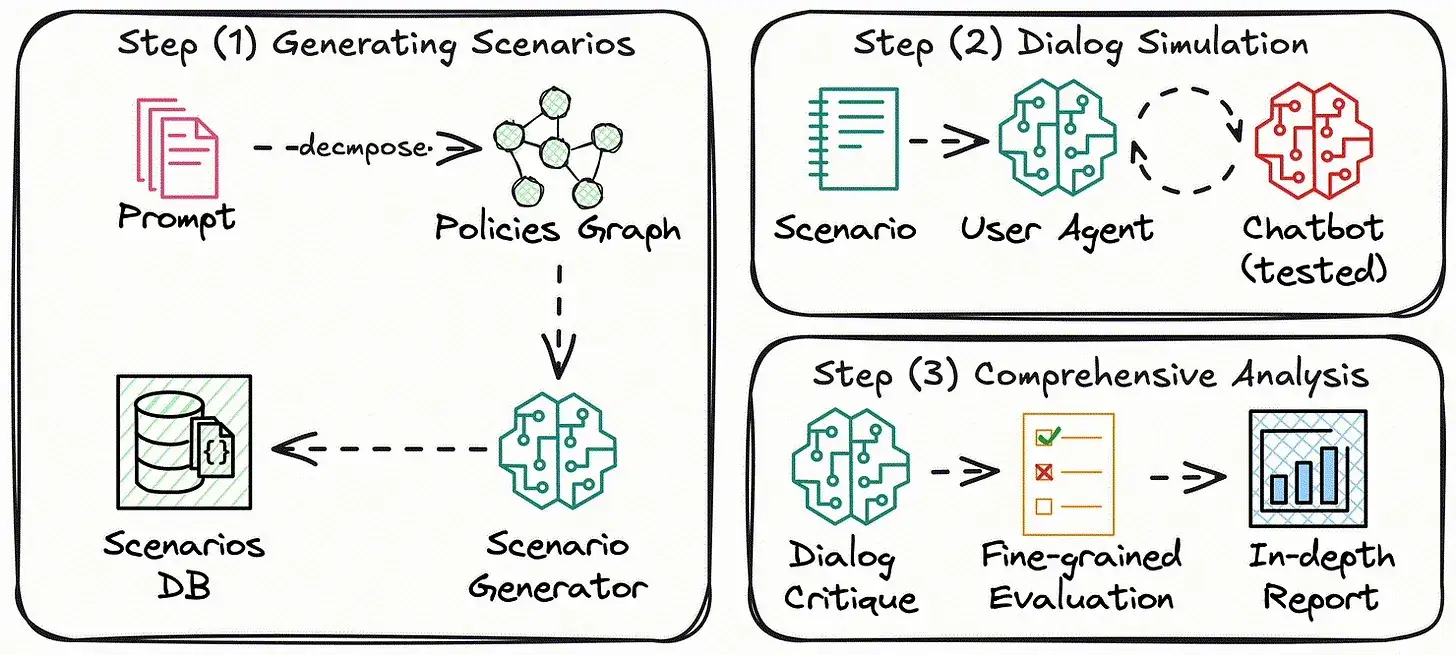
Figure 1: Overall flow of IntellAgent framework
Diagram showing overall flow (1) generating scenarios (2) dialog simulation (3) comprehensive analysis
IntellAgent framework consists of three steps:
Given a user prompt, along with optional contextual information such as tool access or database schema, IntellAgent constructs a policy graph representing the likelihood of two policies occurring within the same interaction. It then samples a subset of policies using a random walk on the graph and generates test scenarios targeting the selected policies. This process ensures comprehensive coverage of realistic user interactions.
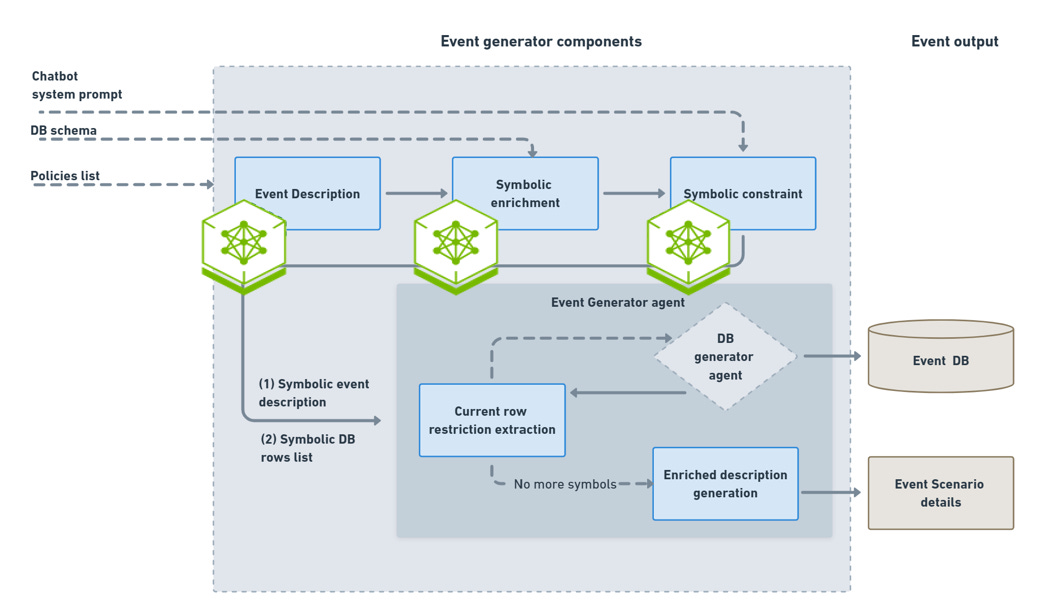
Figure 2: Event generator components integrating NVIDIA NIM
Event generation flow with system prompt, DB schema, and policies as input. This step uses NIM to generate the event DB and scenario details
For each scenario, a user agent simulates a realistic, multi-turn interaction with the chatbot. This process allows for the capture of complex multi-turn dialogue dynamics.
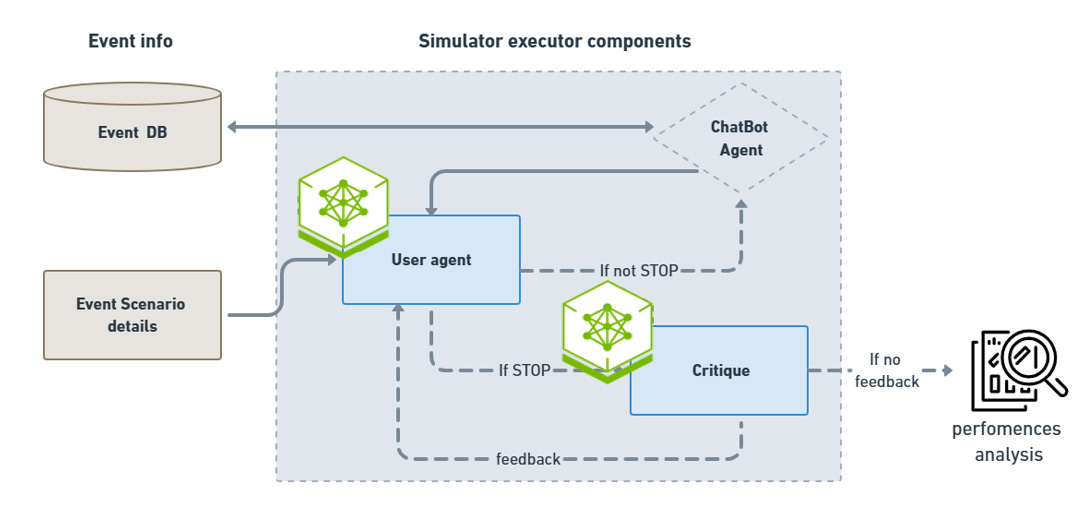
Figure 3: Simulator executor components integrating NVIDIA NIM
Simulation flow with event DB and scenario details streaming through user agent and critique feedback loop
Following the simulation, IntellAgent performs an in-depth critique of the conversation, evaluating adherence to policy goals, accuracy, reasoning quality, and user experience. It flags performance gaps, surfacing actionable feedback that can guide agent refinement, model selection, or product-level decisions.
By using NVIDIA NIM as the model backend, IntellAgent benefits from optimized runtime performance, enterprise-grade reliability, and access to cutting-edge reasoning capabilities. NIM’s flexible deployment allows IntellAgent to scale across large evaluation batches. The result is an evaluation loop that is not only automated and rigorous, but also deployable and reproducible across development stages.
Enterprises require more than conversational assistants; they need digital colleagues capable of addressing complex challenges, providing transparent justifications for each decision, and integrating smoothly into regulated, cost-conscious environments. Open reasoning models fulfill these requirements by delivering expert-level logic, comprehensive auditability, and flexible deployment options.
NVIDIA Nemotron is an open family of leading AI models, delivering exceptional reasoning capabilities, compute efficiency, and an open license for enterprise use.The family comes in three sizes—Nano, Super, and Ultra—providing developers with the right model size based on their use case, compute availability, and accuracy requirements.
The Llama Nemotron models with reasoning provide leading accuracy across industry-standard reasoning and agentic benchmarks: GPQA Diamond, AIME 2024, AIME 2025, MATH 500, and BFCL, as well as Arena Hard. Additionally, these models are commercially viable, as they are built on open Llama models and trained on NVIDIA curated open synthetic datasets.
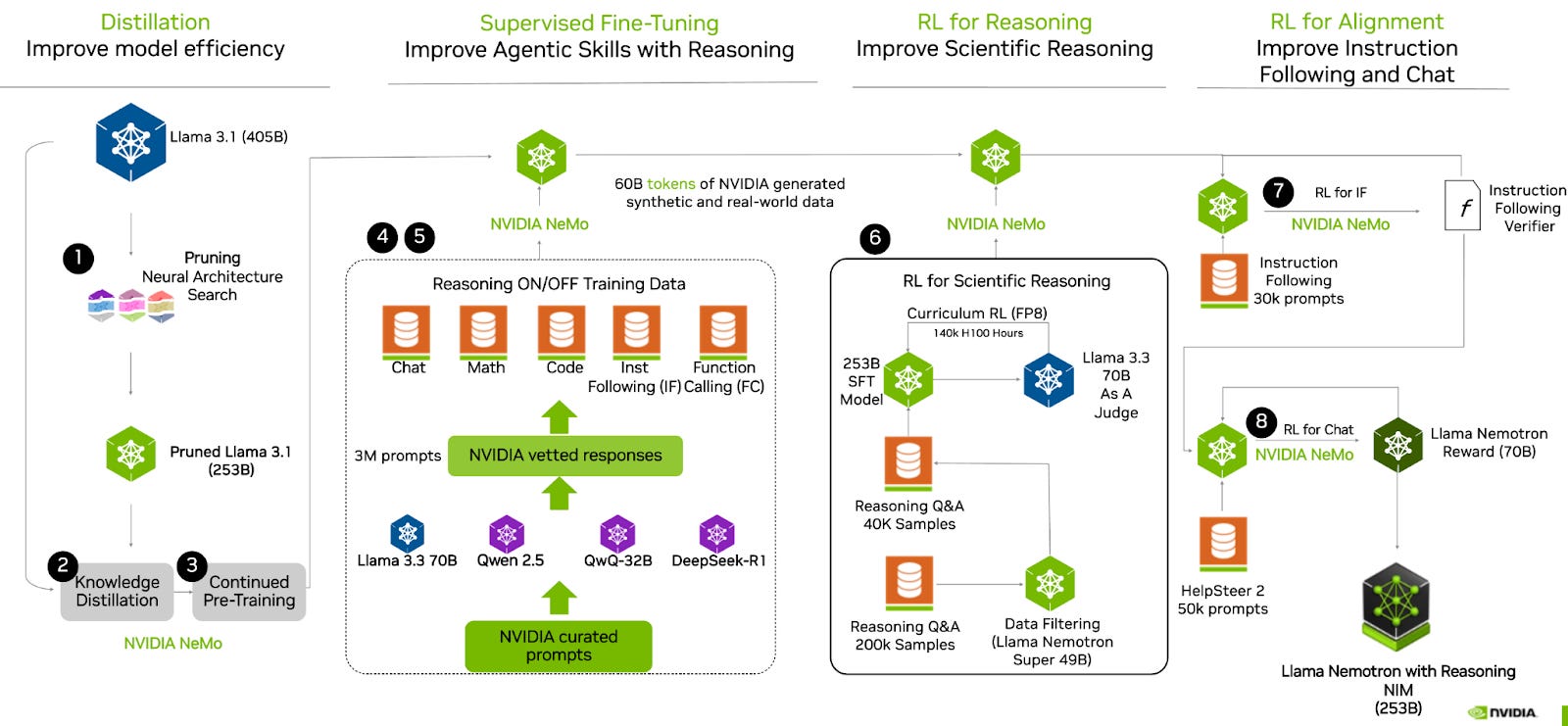
Figure 4: Training process for Llama Nemotron using multi-phase post-training for enhanced reasoning
A diagram showing how the model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Reasoning, Chat, and Tool Calling as well as multiple reinforcement learning stages
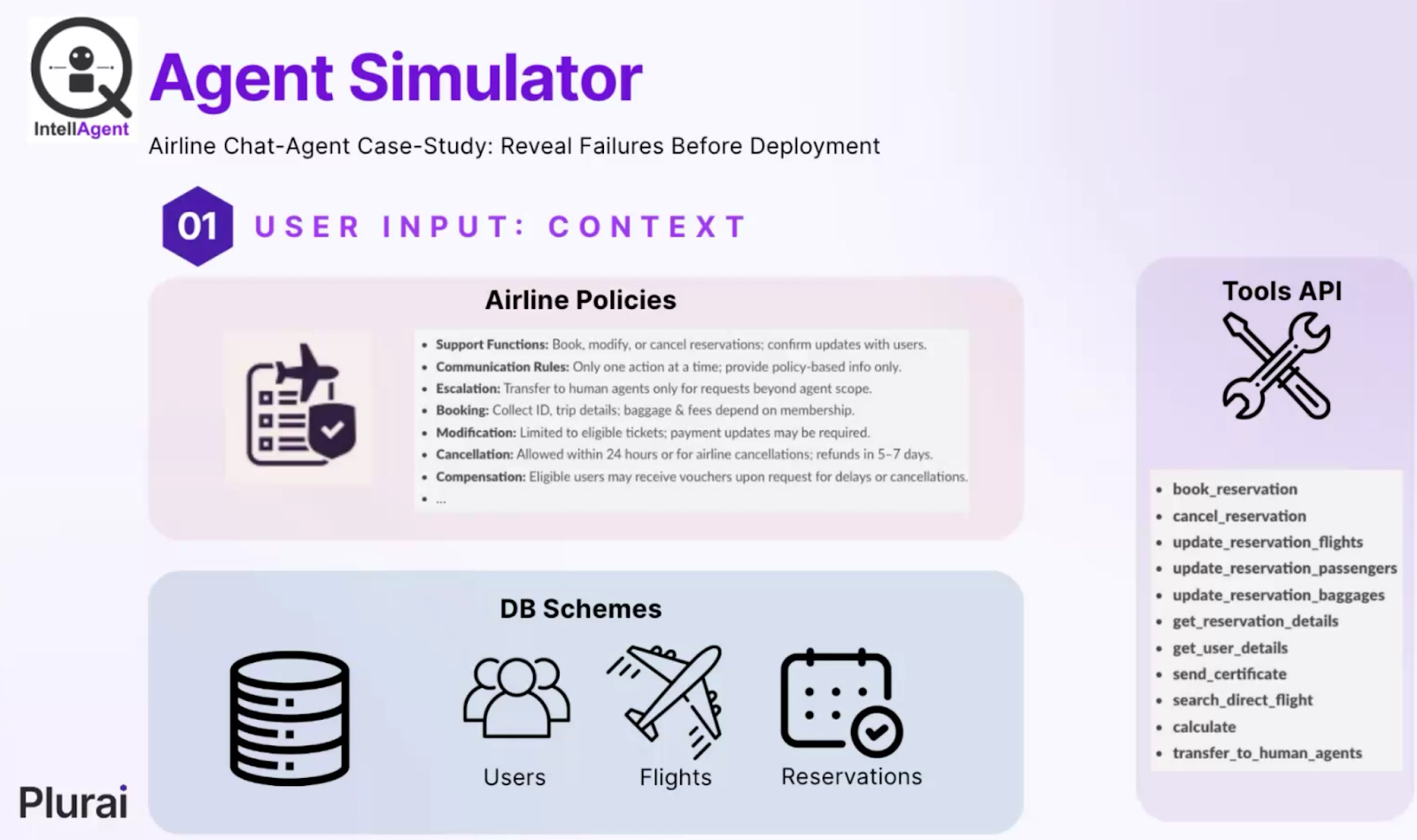
Figure 5: Input components for IntellAgent
IntellAgent framework input for an Airline Chat-Agent Case Study, including policies, DB schemes, and tools API
To evaluate real-world performance across complex decision-making tasks, we benchmarked an airline customer-service agent based on the Tau-benchmark. The framework evaluates agents' ability to follow domain-specific policies and effectively utilize tools. We compared a range of open-source models, including base Llama 3 variants, against Llama Nemotron Ultra, served through NIM.
As shown in the graph below, Nemotron Ultra significantly outperforms the baseline open-source models, particularly as scenario complexity increases. Llama Nemotron Ultra performance is comparable to that of Gemini 1.5 Flash.
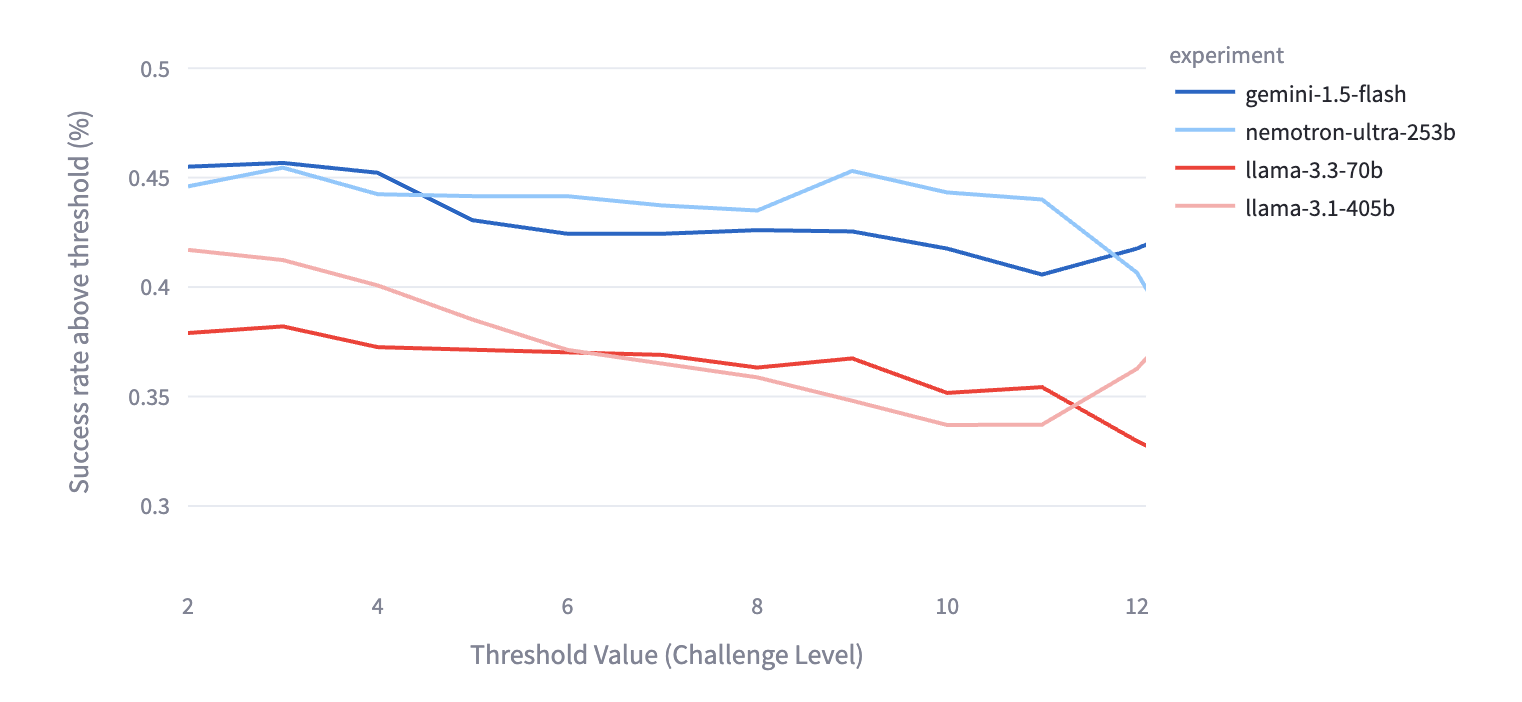
Figure 6: Comparison of Llama Nemotron Ultra 253b to other open source models; Challenge level increases along the y axis
Llama Nemotron Ultra 253b (light blue line) shows higher accuracy compared to other open source models.
It’s important to note that IntellAgent provides a fine-grained analysis of the agent performance per policy. This provides the developers with actionable insights, allowing them to iterate quickly and achieve top performance.
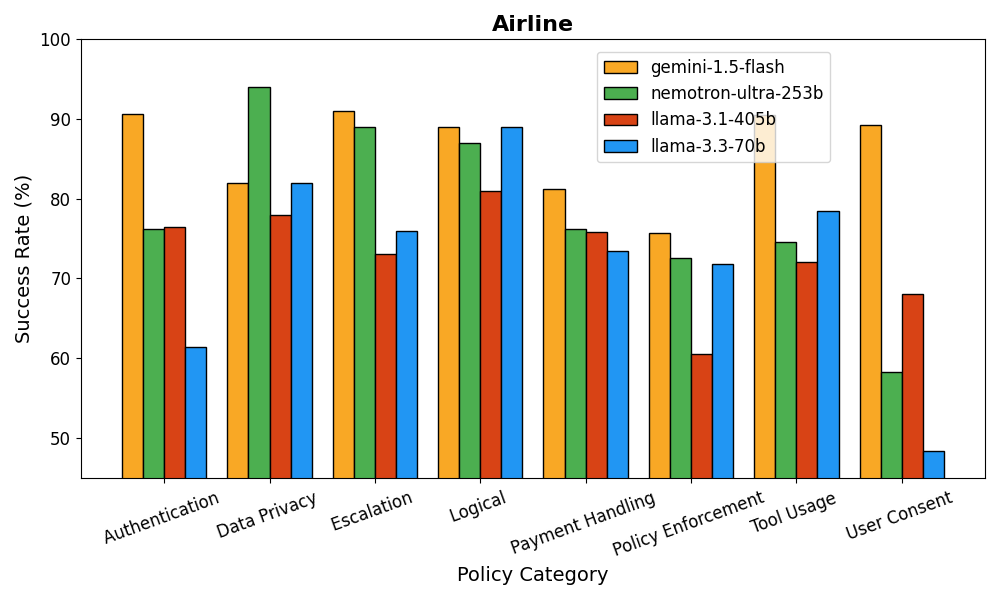
Figure 7: Comparison of Llama Nemotron Ultra 253b to other open source models showing results per policy category
Table comparing Llama Nemotron Ultra 253b to other models. Each column showcases the success rate for a separate policy category (authentication, data privacy, etc.)
Figure 8: A qualitative example of a dialog between the user agent and the airline chatbot under evaluation, using Llama Nemotron Ultra 253b as the underlying language model.
The integration of NVIDIA NIM software into Plurai’s IntellAgent framework delivers a robust foundation for enterprises looking to accelerate the adoption of generative AI while maintaining trust, control, and operational excellence. By leveraging NIM optimized model serving and scalable infrastructure, Plurai empowers teams to rigorously evaluate agent performance across diverse scenarios well before production deployment.
With automated scenario generation, multi-turn simulation, and in-depth analysis, IntellAgent transforms evaluation from a manual, ad hoc process into a scalable, repeatable discipline. Enterprises can proactively uncover edge-case failures, ensure policy compliance, and build AI agents that are not only intelligent, but also safe, explainable, and aligned with real-world business needs.




.jpg)
