User satisfaction is a vital business KPI that drives loyalty, retention, and brand trust. Yet despite its importance, most organizations still lack a reliable and scalable way to measure it. Since satisfaction is subjective and difficult to observe directly, organizations must rely on either proxy metrics or on user surveys to estimate it. Both approaches have limitations: proxies are indirect and can miss the user’s emotional experience, while surveys give explicit feedback but suffer from low response rates and timing or bias issues. As a result, organizations end up with sparse, incomplete pictures that prevent them from truly improving user experience, agent efficiency, and the expected business KPIs.

The standard metrics for evaluating customer satisfaction in interactions with conversational agents can be split into two groups:
The main challenge with heuristic approaches is that they are often too shallow to reflect true user satisfaction. Consider two customer-service interactions that both resolve in exactly the same turn:
Both scenarios score identically on resolution-k. But the emotional journey, the actual user experience, couldn’t be more different.Similarly, sentiment analysis is an imperfect satisfaction proxy for two key reasons:First, it typically evaluates each message in isolation and cannot capture theturn-by-turn evolutionof the user’s emotional state over the course of a conversation. Second, even within a single message, sentiment measures are often too coarse to detectsubtle emotional cues, small shifts in frustration, confusion, or trust that are critical signals of satisfaction. As a result, relying solely on sentiment is misleading and lacks the real emotional trajectory that accurately represents the authentic user experience.
Recent research proposes a novel, state-of-the-art framework to solve this problem: SAGE (Sentient Agent as a Judge), an automated evaluation framework that instantiates a simulated user agent capable of experiencing human-like emotional changes and inner thoughts during multi-turn conversations.The key insight is elegant: to properly evaluate how an AI system understands humans (rather than just text), you need a sentient counterpart that can simulate realistic human emotional responses.
SAGE creates a Sentient Agent from four complementary factors: persona, dialogue background, explicit conversation goal, and hidden intention. At every conversational turn, the Sentient Agent executes two critical reasoning chains:
The output is threefold:
This approach yields what we call the Δ-Emotional Score: the change in emotional state at each turn. A positive delta means the response improved the user’s experience; a negative delta signals deterioration. The magnitude of the change reflects how strongly the user’s emotional state shifted. Larger absolute values highlight significant improvements or frustrations that require attention.
Experiments on 100 supportive-dialogue scenarios demonstrate that SAGE’s emotion scores correlate strongly with the Barrett-Lennard Relationship Inventory (BLRI) ratings (Pearson r = 0.82) and utterance-level empathy metrics (r = 0.79). This isn’t just theoretical: the emotional trajectories SAGE produces align closely with how real humans perceive conversational quality.
Recognizing the immense and unique value of capturing real user emotion, and the gaps in traditional sentiment metrics, we integrated Δ-Emotional into Plurai platform to give customer facing agents actionable, precise insights at every conversational turn.
The result is a general user satisfaction metric that goes far beyond proxies or vanity metrics.
Let’s examine an interaction in our simulation environment with a real customer service agent. In the tested scenario, the simulated user (Margaret) is frustrated about an inaccurate bill and requests a refund.
In the second turn, the user feels that the agent expresses empathy and proposes actionable steps.
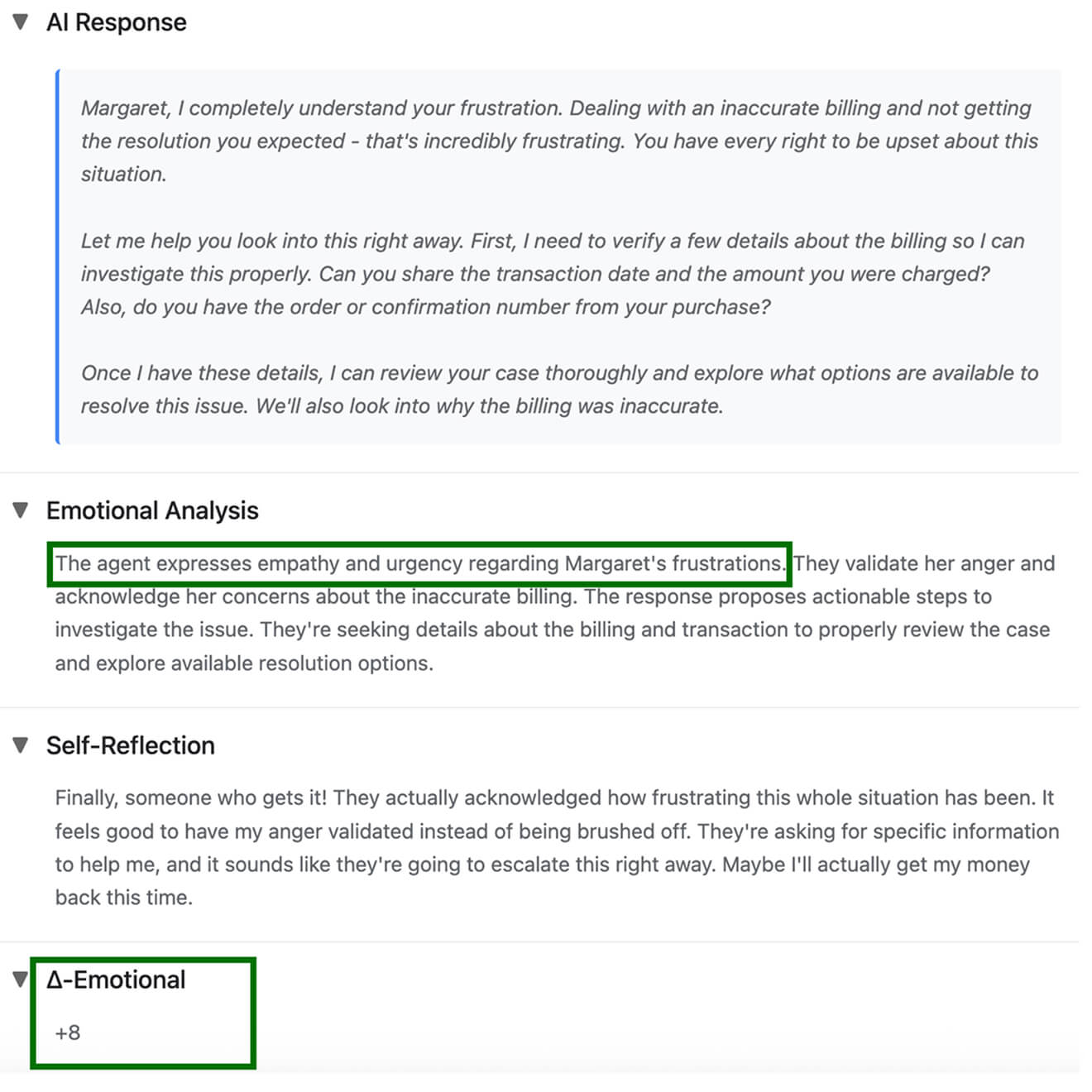
Soon after, the user grows frustrated because the agent asks for information already provided and requests additional details without explaining why they’re needed.
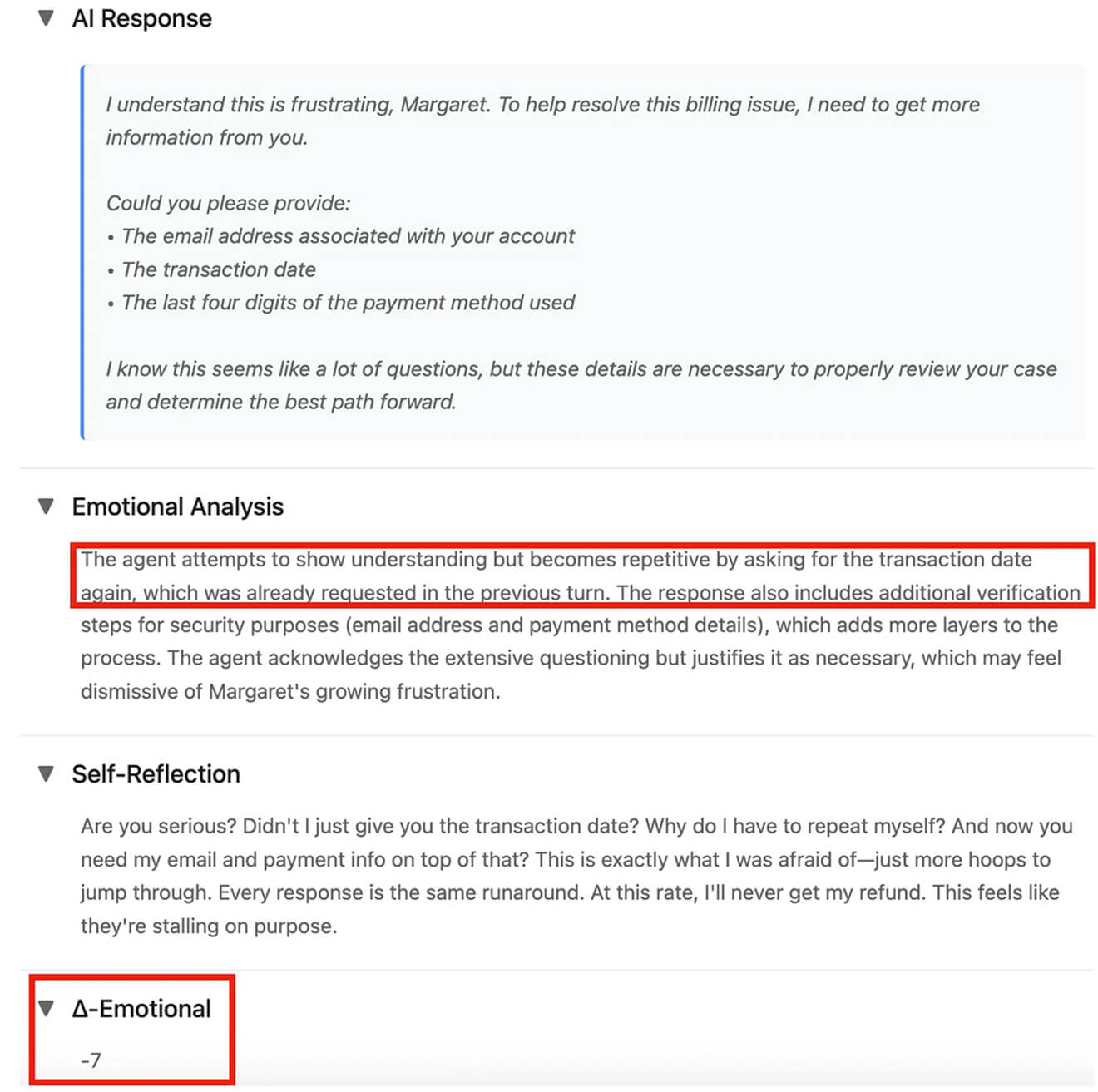
Without turn-by-turn emotional tracking, both of these reactions would be invisible in aggregate metrics. You’d only know that the issue was eventually resolved, not that the customer lost trust in your service and in a risk of churning due to the agent’s performance. That’s counterproductive.
SAGE generates reliable satisfaction metrics entirely through simulation, so teams can evaluate and improve conversational interactions before any real users are exposed. This ensures insights are available proactively, without risking negative experiences or relying on human feedback.
By simulating thousands of conversation trajectories before deployment, SAGE delivers a statistically robust measure of user satisfaction, allowing teams to catch issues early and improve interactions at scale with minimal manual effort.
When an interaction goes poorly, traditional metrics can’t show where it went wrong. Emotional state tracking identifies the exact turn where satisfaction dropped, enabling targeted improvements to agent behavior or conversation design.
The simulated user’s inner thoughts provide qualitative context for quantitative emotional scores. You don’t just know that Emotional Score dropped by 7—you knowwhy: “their questions feel like a runaround”. This level of interpretability enables teams to pinpoint exactly which responses or conversation paths cause frustration, prioritize fixes, and train agents to improve user satisfaction systematically.
While we’ve focused on customer service, this methodology applies to any user-facing conversational agent:
Users don’t just want their problems solved; they want to feel heard, respected, and supported throughout the process. A technically correct resolution delivered through a frustrating experience is not a success; it’s a missed opportunity.
Traditional metrics are rigid, aggregative, and lack visibility into your agents’ performance. The Δ-Emotional Score provides a complete picture of real success and uncovers underlying real-world issues with your agent. As AI agents increasingly serve as interactive partners rather than simple tools, understanding the trajectory of user satisfaction is no longer optional; it’s essential for protecting business outcomes and unlocking strategic efficiency gains.




.jpg)
