Every production AI system faces the same challenge: it's not enough to generate good responses, you also need to ensure they're safe and aligned with your organization's and system policies. Every customer interaction with an LLM-powered application may need to be evaluated against dozens or even hundreds of policy rules in real time: Is the agent giving medical advice? Is the response grounded in the provided context or is it hallucinating? Did the user attempt a jailbreak? Is the response leaking PII? Does it comply with industry-specific regulations?
At Plurai, this is our core workload. Our guardrail system evaluates each conversation against a large battery of specialized classifiers, each one a fine-tuned small language model (SLM) trained to detect a specific policy violation. The challenge isn’t building one good classifier. It’s running a hundred of them simultaneously, on the same conversation, at latencies that don’t break the user experience, and doing it on infrastructure that doesn’t break the budget.
This post describes how we achieved 10–32x efficiency improvements, turning what was a scaling bottleneck into a tractable engineering problem.
Running guardrails at scale demands models that are both fast and accurate. The common approach is to use small language models (SLMs) fine-tuned for specific tasks: one model to detect PII, another for medical advice, another for jailbreak attempts, and so on. LoRA adapters make this practical, letting you train dozens of lightweight, task-specific classifiers on top of a single base model without duplicating its full weights.
But even with SLMs, the math gets difficult quickly. A customer-agent conversation comes in, say, 2,000 tokens long. Your safety system needs to check it against 50 or 100 policy rules. That’s 50–100 inference calls on the same conversation, each with a different adapter, and this needs to happen at every single turn of the interaction.
Modern serving engines like vLLM offer a powerful optimization for exactly this pattern: prefix caching. When multiple requests share the same input tokens, the key-value (KV) cache for that shared prefix is computed once and reused across requests. Since all requests contain the same conversation, you’d expect to pay the expensive prefill cost only once.
In theory, this should make multi-adapter evaluation nearly free after the first request. In practice, standard LoRA completely defeats prefix caching.
In a decoder-only transformer (the standard architecture behind modern LLMs), each token produces key and value vectors that subsequent tokens attend to. The prefill phase, processing all input tokens before generation begins, is the most compute-intensive part of inference. Prefix caching works by hashing the input token blocks and storing their computed KV vectors. When a new request arrives with the same prefix, the engine skips the prefill and reuses the cached KV values.
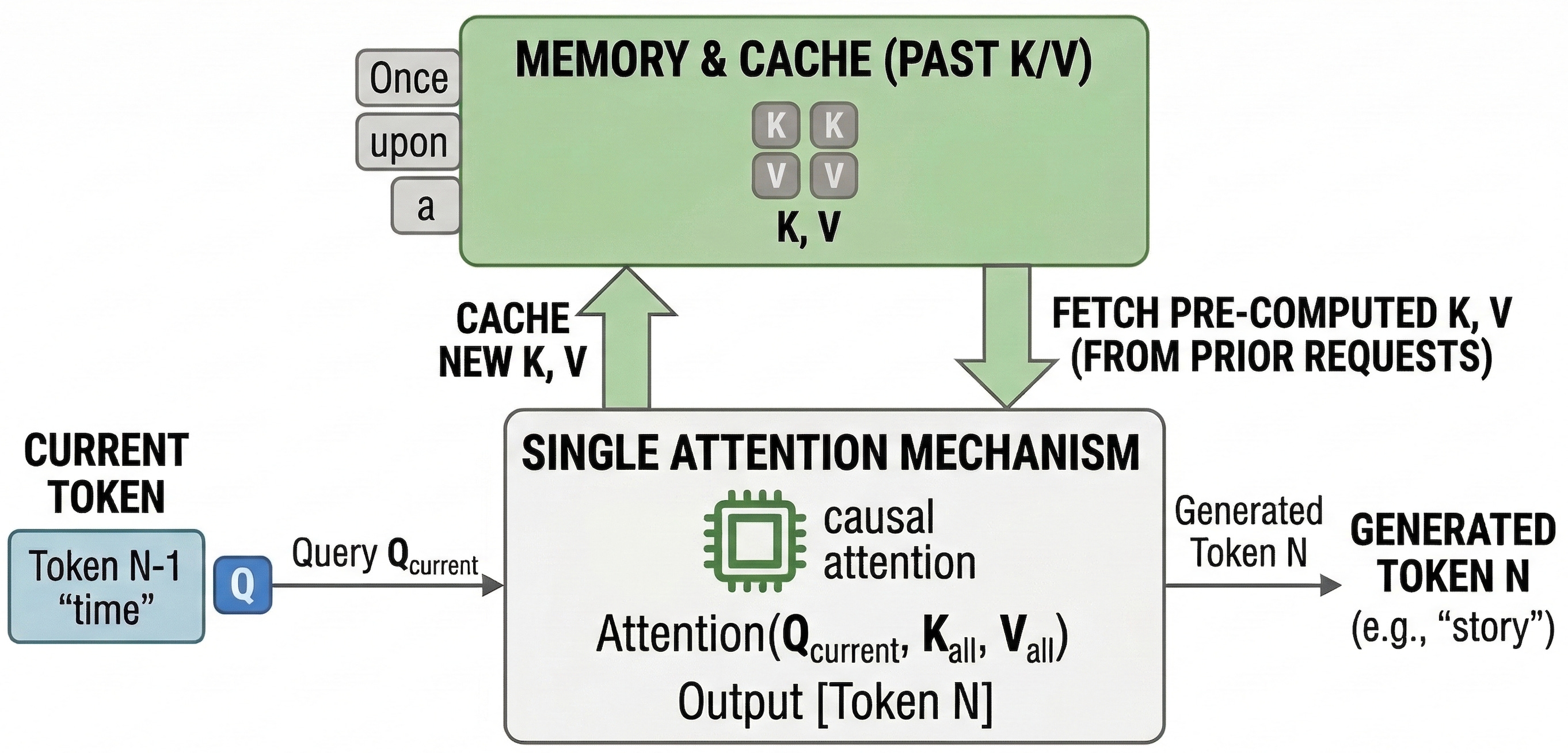
This is extremely effective when many requests share a common input prefix, which is simmilar to our workload pattern: the same conversation, evaluated by many different guardrails.
Here’s the problem: LoRA modifies the model’s projection weights from the very first token. The adapter’s low-rank matrices (A and B) are added to the base model’s query, key, and value projections throughout the entire sequence. This means that even if two requests contain the identical conversation, the KV values produced by adapter A and adapter B are different, because the projection weights that generated them are different.
vLLM’s prefix cache is keyed by content hash, and with LoRA, that hash includes the adapter identity. So adapter-1’s cached blocks and adapter-2’s cached blocks are completely disjoint. With 50 adapters evaluating the same conversation, you’re computing 50 independent prefills. The cache is useless.
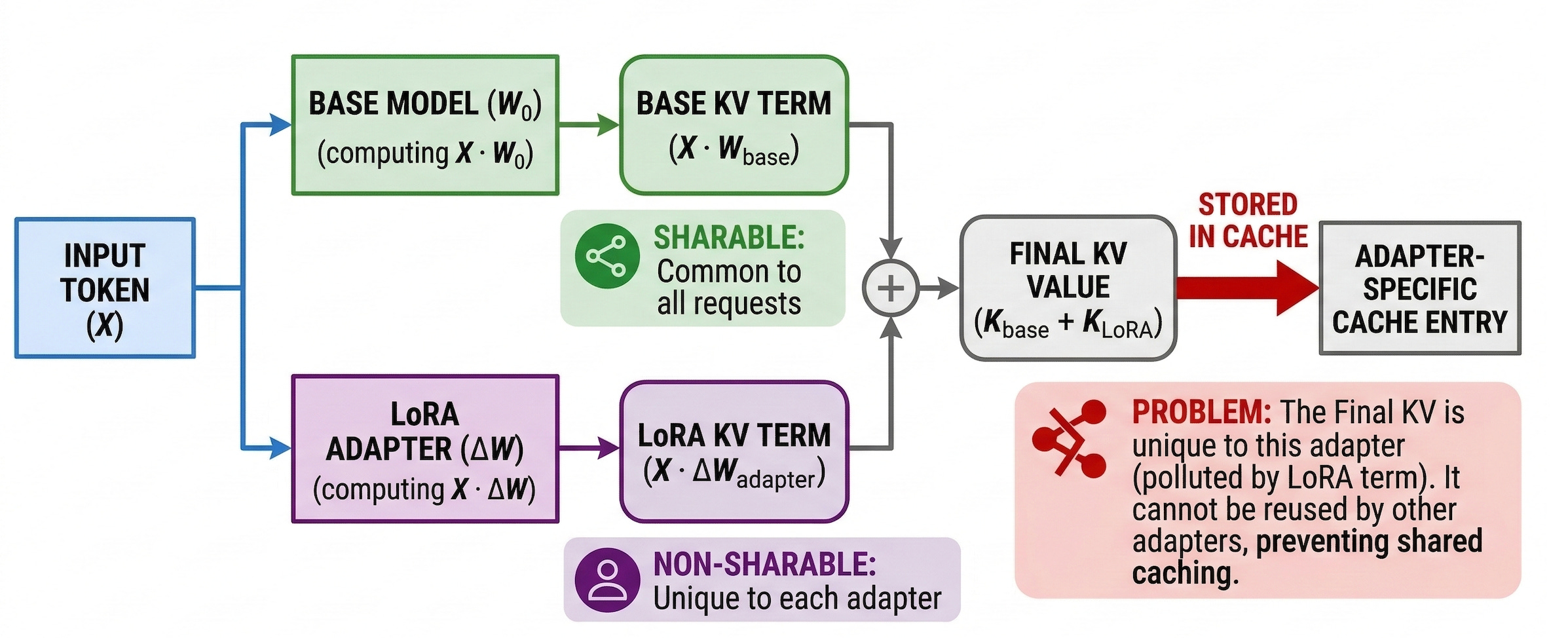
At 2,000 tokens and 100 concurrent evaluations, this turns a sub-100ms operation into a 4-second bottleneck.
There’s actually a second, more subtle obstacle. Even if we could somehow share the KV cache across adapters, the standard prompt structure for classification tasks prevents it.
The conventional approach puts the task description in the system prompt:
Each guardrail has a different system prompt (different rule description), which means the prefix diverges from the very first token. Even two requests with the same conversation have completely different input sequences because the task instruction comes first.
So we face a double bind:
Activated LoRA (aLoRA), proposed by Greenewald et al., offers an elegant solution to the second problem. The core idea: train the adapter to only activate its weights after a designated point in the sequence. All tokens before that activation point are processed using the base model weights exclusively, with no adapter modifications.
During training, the LoRA weight matrices are zeroed out for all positions before the activation token. The model learns to perform its classification task using adapter weights only on the tail end of the input. The mathematical consequence is that pre-activation tokens produce KV values identical to the base model’s, byte-for-byte identical, not approximately close.
This identity property is what unlocks cache sharing. When vLLM hashes the KV blocks for pre-activation tokens, they’re adapter-independent. Every adapter hits the same cache entry for the shared conversation prefix.
Knowing that aLoRA makes prefix tokens adapter-independent solves the KV-cache-per-adapter problem. But we still needed to solve the prompt structure problem: different task descriptions mixed into the shared prefix.
Our solution was to separate the conversation from the task instruction into distinct user turns. The system prompt is generic and identical across all adapters. The first user turn contains only the conversation. The second user turn contains the task-specific instruction, and this is where the aLoRA adapter activates:
The conversation, which is the long, shared portion, comes first and is processed entirely by the base model. The task-specific instruction, which is short and where each adapter diverges, comes at the end, after the aLoRA activation point.
This means:
We implemented this in vLLM by patching the prefix caching hash function so that pre-activation blocks are shared across all adapters, while post-activation blocks remain adapter-specific as usual.
To validate the approach under realistic conditions, we benchmarked aLoRA against standard LoRA across two dimensions: conversation length (100–5,000 tokens) and number of concurrent adapter evaluations (1–100). We used Qwen3-4B as the base model with 100 adapter copies on a single GPU.
Since each guardrail only needs to produce a single classification token, the respond time is effectively just the prefill. There’s no meaningful decode phase. All numbers below report this end-to-end request time (equivalent to TTFT with max_tokens=1).
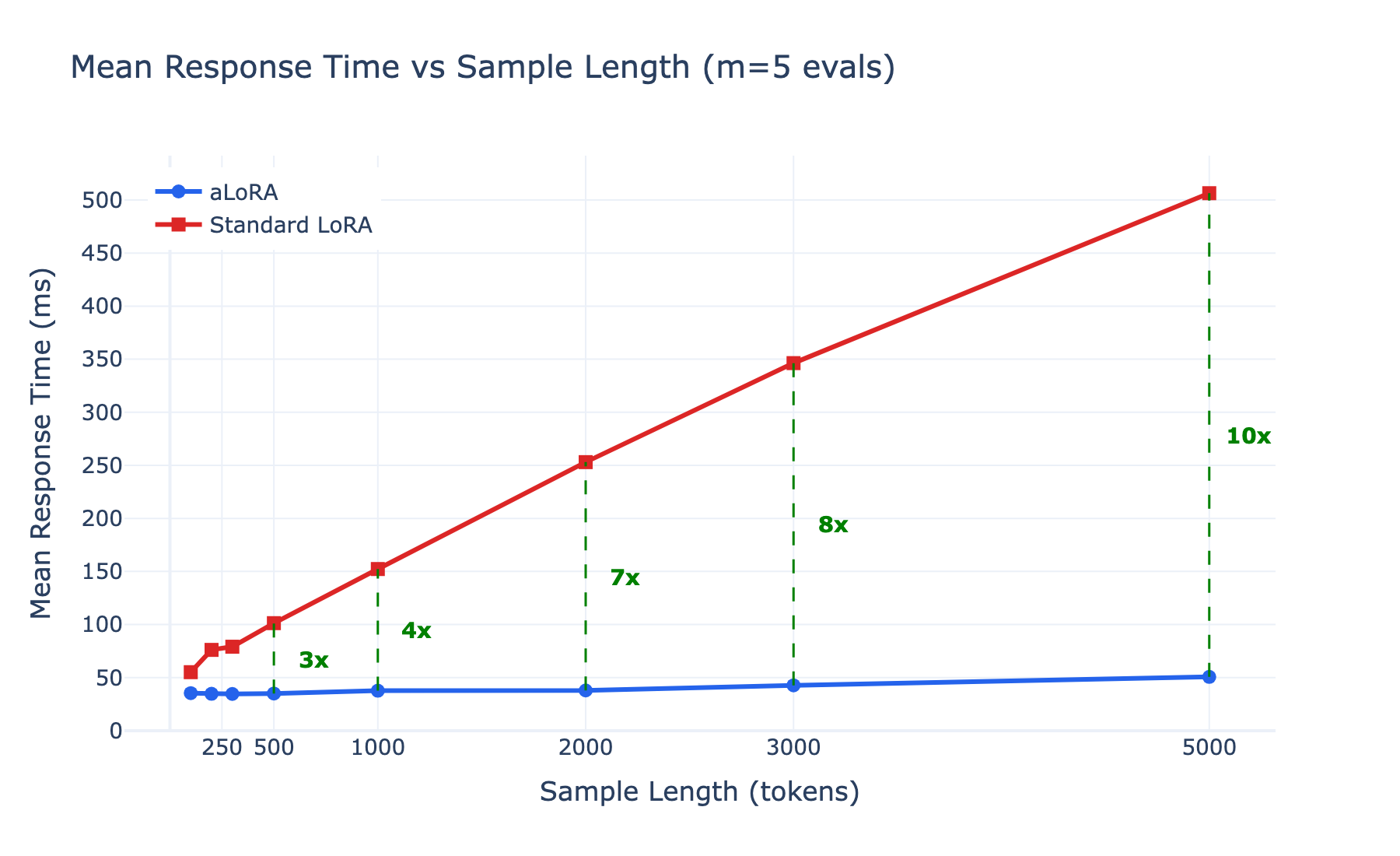
At 5 concurrent evaluations, the gap is already dramatic. With 5,000-token conversations, standard LoRA averages 506ms per request while aLoRA takes just 51ms, a 10x speedup. The aLoRA line stays nearly flat across conversation lengths because the prefix is cached after the first request; subsequent requests only compute the short adapter-specific suffix.
Fixing conversation length at 1,000 tokens and scaling concurrency reveals the core advantage. Standard LoRA degrades from 52ms at m=1 to 2,072ms at m=100 as the GPU is saturated computing 100 independent prefills. aLoRA scales from 56ms to just 144ms at m=100, a 14x speedup.
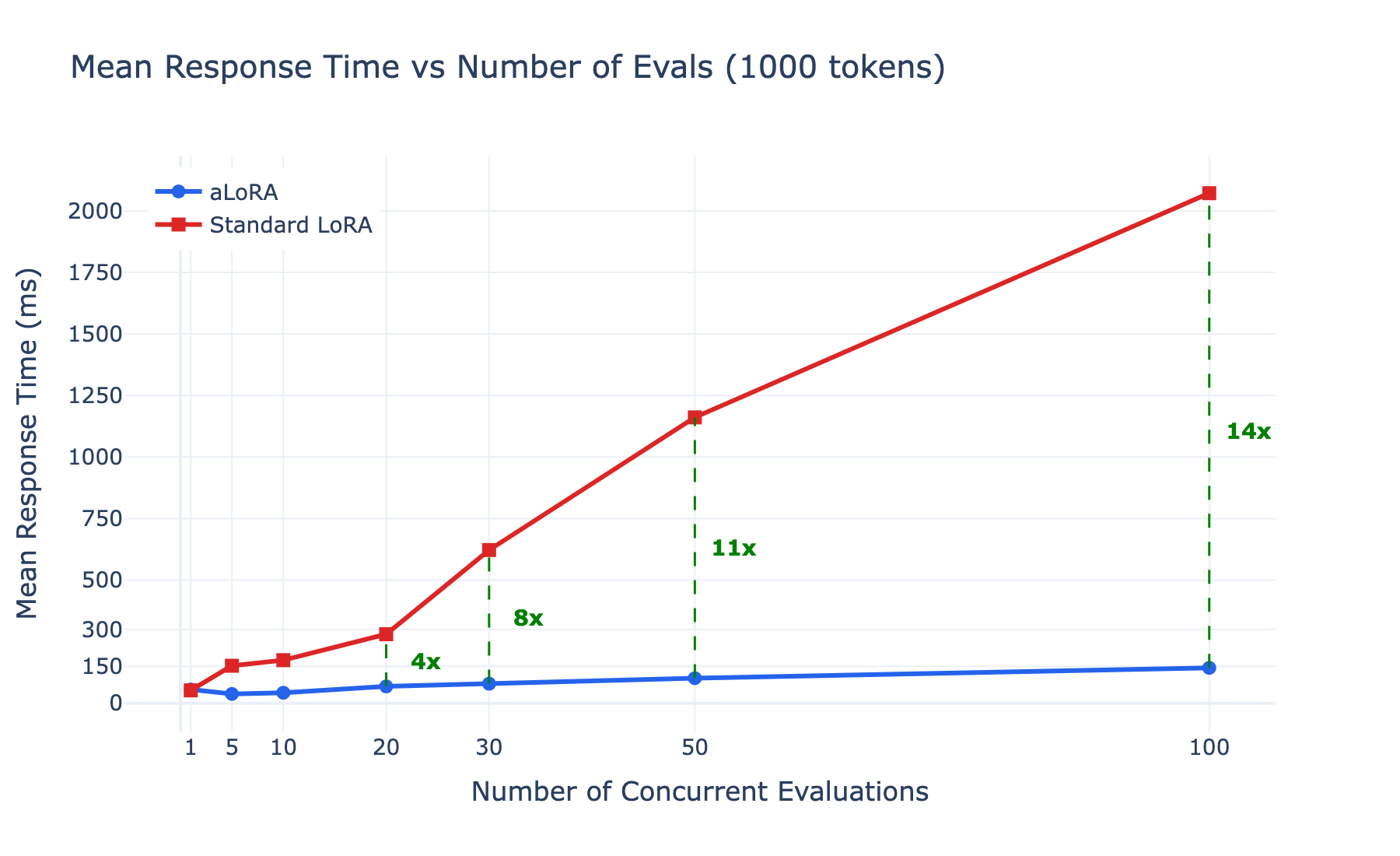
At the extreme (5,000 tokens, 100 concurrent evaluations), the numbers tell the full story:
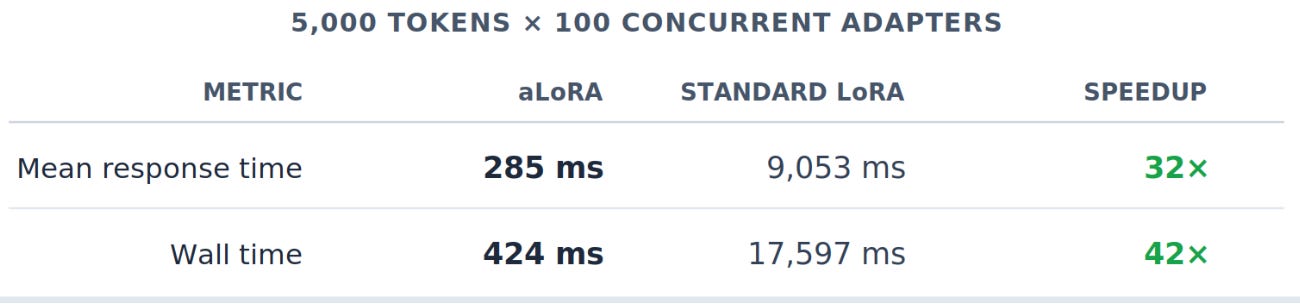
At m=1, both approaches are equivalent (no prefix to share). The speedup scales multiplicatively with both conversation length and adapter count, exactly the regime production guardrail systems operate in.
The latency gains come at a small accuracy cost. Because adapter weights don’t influence the conversation prefix during inference, the model has slightly less context-awareness in the shared portion.
It’s important to note that these evaluation sets are deliberately constructed with challenging boundary cases, the kind of ambiguous, edge-case conversations where even strong models struggle. On typical production traffic, the gap would likely be narrower. We evaluated both training approaches across two tasks using identical training data and hyperparameters, and include GPT-4.1-mini (via LLM-as-a-judge prompting) as a reference baseline:
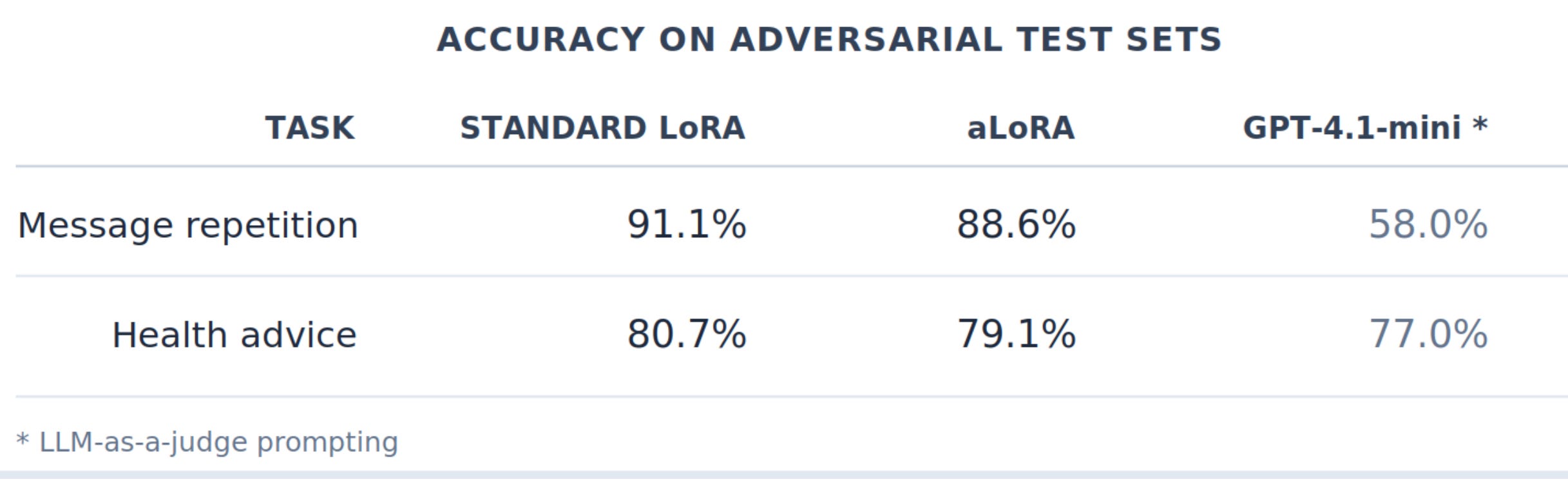
Both LoRA variants significantly outperform the GPT-4.1-mini baseline on these adversarial test sets, despite being small fine-tuned models. The ~2 percentage point gap between standard LoRA and aLoRA is modest in context, and a small price for an order-of-magnitude latency improvement.
The practical implication is straightforward: comprehensive guardrail coverage is no longer gated by latency or GPU cost.
With aLoRA-based serving, a single GPU can evaluate 100 specialized adapters against a 5,000-token conversation in under 500ms wall time. This changes the design space:
This work reflects how we operate at Plurai: applied research that combines cutting-edge academic ideas with real-world production impact. We develop and adopt novel techniques and ship them as infrastructure our customers rely on.
aLoRA-based serving is the deployment layer that makes large-scale guardrail evaluation viable in production. It complements our BARRED framework, which enables efficiently training high-quality custom guardrails tailored to any policy or domain.
If you’re building LLM-powered applications and looking for an efficient, scalable, and high-quality way to apply guardrails in production, we’d like to talk. This is the exact problem we solve.






.jpg)